Setting up PostgreSQL and PostGIS to Run Spatial Queries in R [SQL Database Tutorial]
In this tutorial I will show how to set up PostgreSQL with PostGIS to run spatial queries in R. I cover installation of PostgresSQL, creating schemas, saving data to tables, connecting from R, and running spatial queries.
By Oliver C. Stringham in sql postgres postgis r gis
July 31, 2021
Motivation
I’ve used MySQL for the past 3 years now as my SQL database manager of choice. However, I have two reasons for wanting to learn a new SQL RDMS (relational database management system). First, I would like to be proficient in more than one SQL RDMS. Also, since diving into GIS and the spatial world, I would like to learn PostgreSQL since it supports storing spatial files in an SQL table using the extension PostGIS. In particular, this aspect of PostgreSQL offers much more than most (free) database systems. I think the ability to query using SQL based on spatial operation can be very powerful, especially considering spatial files usually take up a lot space - thus querying to only retrieve needed records is desirable. Also, if storing and retrieving spatial data online (e.g., for web applications), then using SQL is needed to save money on data retrieval and processing time. Here is one example of a spatial query: given a table containing all the counties in the US, query only the counties within 100km of a specific location. We can use the following SQL pseudo-code to achieve this:
SELECT population_size
FROM us_cenesus_county_2010
WHERE ST_DWithin(
geometry,
ST_GeomFromText('POINT(-74.14967 40.79315)', 4269),
100000
);
which will return all the counties within 100 km (100,000 m) from a specified point. This query is visualized below, with a 100km circle added around the point of interest:






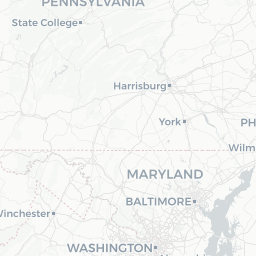

So, instead of loading the entire spatial database, only the subset requested from the query is returned. Hopefully this gives a glimpse of the power of a spatial query. This is what I will work up to in this tutorial - from nothing to being able to run spatial queries in R.
Getting started with PostgreSQL and PostGIS
Installation
First step is to install PostgreSQL (or postgres for short) on your either your local computer or a remote server. For personal use and learning, I recommend installing to your local computer. Visit postgres’ website and select the installation file that matches your operating system. Run the installer, following all the defaults. You need to provide a password - don’t forget it! Once, installation of postgres is complete, it should auto-launch a window to select additional extensions to install. Select then PostGIS extension under spatial extensions and follow the prompts to install. That’s it - postgres and PostGIS are now installed on your computer. Next thing is to set it up postgres to store data.
Data Structure of PostgreSQL
Data is stored in tables. Postgres and other RDMS have a tiered structure of different entities. For postgres, it’s desirable to have one ‘database’ that contains different ‘schema,’ each ‘schema’ can have its own tables. One can use schemas to keep tables organized. For instance, one schema might contain census data tables and another schema might contain weather data tables. Think of a schema as a collection of tables. A ‘database’ can contain multiple schemas. Now is about time where the terminology becomes confusing, but a ‘database’ is higher than a schema, so a database can be a collection of schema. I drew a diagram for this:

Creating Schemas
Before we can store our data in a table(s), we need to first create a schema and then create tables. I’m interested in working with US census data, which is publicly available, so let’s create a schema to eventually have tables with this data. I will demonstrate two ways to create schemas: using pgAmin 4 (a GUI for postgres) and using R.
Using pgAdmin 4 to Create Schemas
Postgres comes with a GUI interface called pgAdmin 4, which allows one to interact with postgres in a point and click manner, which I prefer. On startup of pgAdmin 4 it will ask for the password you provided upon installing postgres. Then click to expand “Servers” (it may ask for password again):

Postgres comes with a ‘database’ built by default called postgres (highlighted in image).
For most data science work, all you need to worry about is schemas and tables. If all your data tables are in the same ‘database’ then they can be queried in the same SQL statement (even if in different schema). So, let’s just stick with the default ‘database’ called postgres. This database comes with a default schema called public which is fine to use. However, let’s walk through creating our own schema.
To create a new schema, right click the postgres database > Create > Schema … . Type in the desired name, in my case it will be called us_census, and click Save.

Now, there exists a new schema called us_census, where we can create data tables to store our data! (Note you might have to right click Schemas and click Refresh for it to show up).

Using R to Create Schemas
To create schemas from R, we first need to create a ‘connection’ to postgres, using the DBI and RPostgres packages:
library(DBI)
library(RPostgres)
# define postgres user password
pw <- "your-password-goes-here"
# create connection to postgres
con <- dbConnect(RPostgres::Postgres(),
host = 'localhost', # host name, can be website/server
port = 5432, # default port of postgres
dbname = 'postgres', # name of database in postgres
user = 'postgres', # the default user
password = pw # password of user
)
To create a schema in R use:
dbSendQuery(con, "CREATE SCHEMA us_census;")
To check if the query worked, use:
dbGetQuery(con, "SELECT schema_name
FROM information_schema.schemata;")
## schema_name
## 1 pg_toast
## 2 pg_catalog
## 3 public
## 4 information_schema
## 5 us_census
Gather Data: US census data
Before going any further, let’s first get some data to eventually store in our SQL table. For this tutorial, let work with 2010 US census data at the county level. We’ll collect the following: population size, and the spatial files for counties. US census data is available for download
here - however, the R package tidycensus (
link) provides a very interface to download the data and the package tigris (
link) lets us easily download the spatial files of the counties.
First let’s load in packages needed here:
library(tidycensus)
library(tigris)
library(tidyverse)
library(sf)
In order to download census data via tidycensus, you have to get an API code
here. Once they email it to you (took a few minutes for me), set the key in R with the following:
census_api_key("YOUR API KEY GOES HERE")
Let’s view the variables available in the 2010 US census:
variables_d2010 = load_variables(2010, "sf1")
head(variables_d2010)
## # A tibble: 6 x 3
## name label concept
## <chr> <chr> <chr>
## 1 H001001 Total HOUSING UNITS
## 2 H002001 Total URBAN AND RURAL
## 3 H002002 Total!!Urban URBAN AND RURAL
## 4 H002003 Total!!Urban!!Inside urbanized areas URBAN AND RURAL
## 5 H002004 Total!!Urban!!Inside urban clusters URBAN AND RURAL
## 6 H002005 Total!!Rural URBAN AND RURAL
I’ll download just 3 variables: total population, total population of white alone, and median age of every county in the US.
# Define which variables I want
v10 = c("P001001", # Total population
"P003002", # Total population white alone
"P013001" # Median age both sexes
)
# Download data from US census (requires Internet connection)
df <- get_decennial(geography = "county", # at the level of county
variables = v10,
year = 2010,
output = "wide" # gives one column per variable
)
head(df)
## # A tibble: 6 x 5
## GEOID NAME P001001 P003002 P013001
## <chr> <chr> <dbl> <dbl> <dbl>
## 1 05131 Sebastian County, Arkansas 125744 96344 36.7
## 2 05133 Sevier County, Arkansas 17058 11949 33.7
## 3 05135 Sharp County, Arkansas 17264 16582 47
## 4 05137 Stone County, Arkansas 12394 11995 47.7
## 5 05139 Union County, Arkansas 41639 26276 40.1
## 6 05141 Van Buren County, Arkansas 17295 16598 46.6
Now download the geometries of each county from the tigris package:
geoms = counties(cb = TRUE, year = 2010)
head(geoms)
## Simple feature collection with 6 features and 6 fields
## geometry type: MULTIPOLYGON
## dimension: XY
## bbox: xmin: -86.70279 ymin: 30.99324 xmax: -85.30444 ymax: 33.9642
## geographic CRS: NAD83
## GEOID STATEFP COUNTYFP state state_name county
## 1 01029 01 029 AL Alabama Cleburne County
## 2 01031 01 031 AL Alabama Coffee County
## 3 01037 01 037 AL Alabama Coosa County
## 4 01039 01 039 AL Alabama Covington County
## 5 01041 01 041 AL Alabama Crenshaw County
## 6 01045 01 045 AL Alabama Dale County
## geometry
## 1 MULTIPOLYGON (((-85.38872 3...
## 2 MULTIPOLYGON (((-86.03044 3...
## 3 MULTIPOLYGON (((-86.00928 3...
## 4 MULTIPOLYGON (((-86.34851 3...
## 5 MULTIPOLYGON (((-86.14699 3...
## 6 MULTIPOLYGON (((-85.79043 3...
From there, I’ll join the census data to the geometries and select the desired wanted columns.
# join in State Name
data("fips_codes")
geoms = geoms %>%
left_join(fips_codes, by = c("COUNTYFP"="county_code", "STATEFP"="state_code")) %>%
mutate(GEOID = str_extract(GEO_ID, "[0-9]+$")) %>% # adjust GEO_ID column to match other census data
select(GEOID, STATEFP, COUNTYFP,
state, state_name, county, geometry)
# Combine census data with geometries
df_w_geom = df %>%
left_join(geoms, by = "GEOID") %>%
st_as_sf()
# re order & rename columns
df_w_geom = df_w_geom %>%
select(GEOID, STATEFP:county, P001001:P013001, geometry) %>%
rename(STATE_ABB = state,
STATE_NAME = state_name,
COUNTY_NAME = county) %>%
rename_all(tolower) # all columns to lowercase for postgres
head(df_w_geom %>% st_drop_geometry())
## Simple feature collection with 6 features and 9 fields
## geometry type: MULTIPOLYGON
## dimension: XY
## bbox: xmin: -94.47732 ymin: 33.00816 xmax: -91.25858 ymax: 36.49756
## geographic CRS: NAD83
## # A tibble: 6 x 10
## geoid statefp countyfp state_abb state_name county_name p001001 p003002
## <chr> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
## 1 05131 05 131 AR Arkansas Sebastian ~ 125744 96344
## 2 05133 05 133 AR Arkansas Sevier Cou~ 17058 11949
## 3 05135 05 135 AR Arkansas Sharp Coun~ 17264 16582
## 4 05137 05 137 AR Arkansas Stone Coun~ 12394 11995
## 5 05139 05 139 AR Arkansas Union Coun~ 41639 26276
## 6 05141 05 141 AR Arkansas Van Buren ~ 17295 16598
## # ... with 2 more variables: p013001 <dbl>, geometry <MULTIPOLYGON [°]>
OK, the data is all ready! We have 10 columns: 3 containing the census variables I chose, 6 with the codes or names, and 1 with the geometry as simple feature data type.
Creating Tables & Writing Data to Tables
Once a schema is created, we can create a table that will eventually store our data. Here is where data storage can differ compared to excel/csv data sheets. One approach is to manual specify SQL tables, which involves specifying the names of the columns along with the data types (e.g., numeric, text, logical) of the columns. This approach allows for greater flexibility and optimized data storage, which may be required if new data will be continuous added to the table or if being used in web applications. However, if you don’t care too much about the inner workings of SQL tables and just want to create a one time table, there is a quicker way. I will detail both the quick way and long way below.
The Quick Way to Create a Table: Direct Export from R
The quick way to create a table is to export the data directly from R. The first step is to create a ‘connection’ to postgres in R using the DBI and RPostgres packages. Note in this case, we specify what schama to connect to using the options parameter.
library(DBI)
library(RPostgres)
# define postgres user password
pw <- "your-password-goes-here"
# create connection to postgres
con <- dbConnect(RPostgres::Postgres(),
host = 'localhost', # host name, can be website/server
port = 5432, # default port of postgres
dbname = 'postgres', # name of database in postgres
user = 'postgres', # the default user
password = pw, # password of user
options="-c search_path=us_census" # specify what schema to connect to
)
Before we can create a new table, we must first activate the PostGIS extension in postgres. This can be done easily once a connection is created:
dbSendQuery(con, "CREATE EXTENSION postgis SCHEMA us_census;")
Now let’s save (or ‘write’) our dataframe to a new postgres table using the sf package’s st_write:
st_write(obj = df_w_geom,
dsn = con,
Id(schema="us_census", table = "us_census_county_2010"))
The DBI package also supports writing tables and is probably preferred when not working with spatial data (code not run):
dbWriteTable(con,
name = "us_census_county_2010",
value = df_w_geom)
Let’s check to see if it worked by first seeing if the table exists:
dbListTables(con)
## [1] "us_census_county_2010_v2" "geography_columns"
## [3] "geometry_columns" "spatial_ref_sys"
## [5] "us_census_county_2010"
You’ll see our table us_census_county_2010 along with other tables that PostGIS added and are required. Now, let’s check the the data was written correctly using st_read to load it from postres to R:
test = st_read(con, "us_census_county_2010")
head(test)
## Simple feature collection with 6 features and 9 fields
## geometry type: MULTIPOLYGON
## dimension: XY
## bbox: xmin: -123.0241 ymin: 33.75099 xmax: -91.25858 ymax: 38.32121
## geographic CRS: NAD83
## geoid statefp countyfp state_abb state_name county_name p001001 p003002
## 1 05131 05 131 AR Arkansas Sebastian County 125744 96344
## 2 05133 05 133 AR Arkansas Sevier County 17058 11949
## 3 05135 05 135 AR Arkansas Sharp County 17264 16582
## 4 06039 06 039 CA California Madera County 150865 94456
## 5 06041 06 041 CA California Marin County 252409 201963
## 6 05137 05 137 AR Arkansas Stone County 12394 11995
## p013001 geometry
## 1 36.7 MULTIPOLYGON (((-94.4379 35...
## 2 33.7 MULTIPOLYGON (((-94.4749 34...
## 3 47.0 MULTIPOLYGON (((-91.40714 3...
## 4 33.0 MULTIPOLYGON (((-119.7529 3...
## 5 44.5 MULTIPOLYGON (((-122.4187 3...
## 6 47.7 MULTIPOLYGON (((-92.14328 3...
And there it is, the quick way to save data to postgres. The long way will help with optimizing table sizes and develop a deeper understanding of SQL in general. But, if you don’t care about the long way, skip to the next section.
The Long Way to Create a Table: Manual Specification
Figuring Out Data Types of Columns
Let’s view the columns and their data types in R:
df_w_geom %>%
map(class)
## $geoid
## [1] "character"
##
## $statefp
## [1] "character"
##
## $countyfp
## [1] "character"
##
## $state_abb
## [1] "character"
##
## $state_name
## [1] "character"
##
## $county_name
## [1] "character"
##
## $p001001
## [1] "numeric"
##
## $p003002
## [1] "numeric"
##
## $p013001
## [1] "numeric"
##
## $geometry
## [1] "sfc_MULTIPOLYGON" "sfc"
Great, so the first 6 columns are character, the next 3 are numeric and the last is mulitpolygon. Now, we need slightly more specific information about the data types, since this is what is required in for an SQL table. See here for a list of postgres data types. Let’s start with the character columns. We need to know the length of the longest string. If you look under character data types in postgres, you’ll see there are 3 different character data types: varchar, char, and text. For our purposes, we’ll use varchar. We could be lazy and just use the text data type since it can handle characters of unlimited length, however, choosing text over varchar would result in the database being larger (in storage space) that needed. Now, we just need to know the maximum length of each column. Let’s find that out in R:
df_w_geom %>%
st_drop_geometry() %>%
select_if(is.character) %>%
map(~max(nchar(.)))
## $geoid
## [1] 5
##
## $statefp
## [1] 2
##
## $countyfp
## [1] 3
##
## $state_abb
## [1] 2
##
## $state_name
## [1] 20
##
## $county_name
## [1] 33
Perfect, we will use these values to populate the script to create a postgres SQL table. Now, let’s move on the numeric columns. Similar to the character columns, we first need to know the maximum size. But, we also need to know if decimal places are involved:
df_w_geom %>%
st_drop_geometry() %>%
select_if(is.numeric) %>%
map(~max(.))
## $p001001
## [1] 9818605
##
## $p003002
## [1] 4936599
##
## $p013001
## [1] 62.7
Looking through the numeric postgres data types, we can see that the integer data type will work for columns P001001 and P003002. Since P013001 has one decimal place, we’ll use numeric data type, where we’ll set the precision (total number of digits) to 3 and scale (number of decimal places) to 1.
Now on to the last and most special data type: geography. This data type is handled by PostGIS, an extension of postgres. View the different types of geography data types here. In this case, we need to know what kind of geometry (point, line, polygon, multipolygon, etc.) and the spatial reference system. We already know our geometry is multipolygon. Let’s figure out the spatial reference system in R:
df_w_geom %>%
st_crs()
## Coordinate Reference System:
## User input: NAD83
## wkt:
## GEOGCRS["NAD83",
## DATUM["North American Datum 1983",
## ELLIPSOID["GRS 1980",6378137,298.257222101,
## LENGTHUNIT["metre",1]]],
## PRIMEM["Greenwich",0,
## ANGLEUNIT["degree",0.0174532925199433]],
## CS[ellipsoidal,2],
## AXIS["latitude",north,
## ORDER[1],
## ANGLEUNIT["degree",0.0174532925199433]],
## AXIS["longitude",east,
## ORDER[2],
## ANGLEUNIT["degree",0.0174532925199433]],
## ID["EPSG",4269]]
We can see we’re working with the NAD83 coordinate reference system, which is common for US-wide spatial data. What we need to know is the EPGS number on the last line of the above output: 4269.
Specifying Table
We now know the data types for all our columns. Yay! Now, we can construct and SQL statement that will create our table. For simplicity, let me first just write SQL statement:
CREATE TABLE us_census.us_census_county_2010 (
id serial primary key,
geoid varchar(5),
statefp varchar(2),
countyfp varchar(3),
state_abb varchar(2),
state_name varchar(20),
county_name varchar(33),
p001001 integer,
p003002 integer,
p013001 numeric(3, 1),
geometry geography(MultiPolygon, 4269)
);
CREATE TABLE creates a new table. Followed after that is the name we want to call the table: us_census_county_2010. In addition, we need to specify the schema to create the table in, that is why us_census. is placed before the table name. Next, each column is specified along with their data types.
The first column in SQL tables is usually a unique identifier; I called this column id. The term serial is a data type equivalent to an auto-increment integer, meaning that as new rows are adding to the table, id will increase by units of 1 (starting at 1). The primary key term indicates that this column is a unique identifier and that no two values of id can repeat in another row. In general, all SQL tables have a primary key. Note, a primary key wasn’t created in the quick way. I have to look into if this is possible or not.
The next 6 column names and data types come directly from what we worked on above. Each are varchar data type and the number inside the parentheses indicates the length of the longest string. I decided to use the exact number here because I know that the data will not change. If I thought the maximum length would increase as more data was added, I would account for that by making that number larger. For example, if I thought new counties will be added to the table in the future, I might change county_name from varchar(33) to varchar(50) to account for potentially longer county names. Note: the maximum character length can always be adjusted later.
The next 3 columns are the numeric columns, as discussed in above.
The last column is what will store the spatial information. The column is called geometry and the data type is geography. The syntax here is the first parameter is the type of geography (point, line, polygon, etc.) and the second parameter is the EPGS code of the spatial coordinate system (4269 in this case).
Running the Script to Create the Table
Activate PostGIS
If you haven’t already activated PostGIS in R (showed above), do so now:
dbSendQuery(con, "CREATE EXTENSION postgis SCHEMA us_census;")
Note: activating PostGIS only needs to be done one time ever, per schema.
Running the SQL statement
Now let’s run the CREATE TABLE statement from R. I’ll call it a slightly different name, so we can compare with the table made before:
dbSendQuery(con,
"CREATE TABLE us_census.us_census_county_2010_v2 (
id serial primary key,
geoid varchar(5),
statefp varchar(2),
countyfp varchar(3),
state_abb varchar(2),
state_name varchar(20),
county_name varchar(33),
p001001 integer,
p003002 integer,
p013001 numeric(3, 1),
geometry geography(MultiPolygon, 4269)
);"
)
Let’s double check that the tables was made:
dbListTables(con)
## [1] "us_census_county_2010_v2" "geography_columns"
## [3] "geometry_columns" "spatial_ref_sys"
## [5] "us_census_county_2010"
All good, we can see us_census_county_2010_v2 was created (although it was already there before because I ran the code prior to posting the tutorial). Now, on the the important part … adding data to the table!
Adding Data to a Table
We will add data to our postgres table using R, since that is where we collecting and curated the data already. We’ll use the same up as before:
library(DBI)
library(RPostgres)
library(sf)
pw <- "your-password-goes-here"
con <- dbConnect(RPostgres::Postgres(),
host = 'localhost', # host name, can be website/server
port = 5432, # default port of postgres
dbname = 'postgres', # name of database in postgres
user = 'postgres', # the default user
password = pw, # password of user
options="-c search_path=us_census" # specify what schema to connect to
)
Now, we’ll add the data the same way did before, except specify append = TRUE, which tells postgres to add new rows instead of creating a new table:
dbWriteTable(con,
name = "us_census_county_2010_v2",
value = df_w_geom,
append = TRUE)
And finally, let’s check the data was saved properly to postgres by loading it back into R:
test2 = st_read(con, "us_census_county_2010_v2", geometry_column ='geometry')
head(test2 %>% tibble())
## # A tibble: 6 x 11
## id geoid statefp countyfp state_abb state_name county_name p001001 p003002
## <int> <chr> <chr> <chr> <chr> <chr> <chr> <int> <int>
## 1 1 05131 05 131 AR Arkansas Sebastian ~ 125744 96344
## 2 2 05133 05 133 AR Arkansas Sevier Cou~ 17058 11949
## 3 3 05135 05 135 AR Arkansas Sharp Coun~ 17264 16582
## 4 30 06039 06 039 CA California Madera Cou~ 150865 94456
## 5 31 06041 06 041 CA California Marin Coun~ 252409 201963
## 6 4 05137 05 137 AR Arkansas Stone Coun~ 12394 11995
## # ... with 2 more variables: p013001 <dbl>, geometry <MULTIPOLYGON [°]>
All looks good. Note, in this case, we need to specific geometry_column ='geometry' for the st_read function. I’m not sure why it’s needed here and not in the other method.
Running Spatial Queries to Postgres from R
I mentioned in the introduction one of the great benefits of postgres and PostGIS is that all the tools of SQL are available to use. I’ll show one here, selecting polygons within a certain distance of a point. Spatial queries can be added to the st_read function with the parameter query=.
Let’s select all the counties with 100 kilometers of where I was born, Belleville, New Jersey:
counties_query =
st_read(con,
query =
"SELECT * FROM us_census_county_2010
WHERE ST_DWithin(geometry::geography,
ST_GeomFromText('POINT(-74.14967 40.79315)', 4269)::geography, 100000);"
)
The PostGIS function used to query within a distance is called ST_DWithin, whose inputs are: geometry column of table, the point of where to calculate the distance, and the distance buffer. Since the projection of our SQL table is NAD83, the units of the buffer will be in degrees - which is really not that useful. However, we can easily adjust the function to use meters instead, by placing ::geography after the geometry columns and point specification. Since we used the ::geometry notation our buffer distance is now 100km (100,000 m).
Let’s view our results here by plotting the population size of each county returned in the query:
library(mapview)
# define sf point where Belleville is
belleville = st_sfc(st_point(c(-74.14967, 40.79315)), crs = 4269)
# define 100km around Belleville
belleville_buffer = st_buffer(belleville %>% st_transform("ESRI:102003"), 100000 ) # transform to a crs with units of meters in order to buffer in meters
# plot Population size and Belleville Buffer
map1 =
mapview(belleville,
col.regions = "red",
label = "Belleville Township, NJ",
layer.name = "Belleville Township, NJ") +
mapview(belleville_buffer, color = "red", alpha.regions = 0,
label = "Belleville 100km Buffer",
layer.name = "Belleville 100km Buffer") +
mapview(counties_query,
zcol = "p001001",
label = paste0(counties_query$county_name, ", ", counties_query$state_abb),
layer.name = "Population Size")
map1
We can visually see that the query worked! Note that ST_DWithin will return counties that intersect with the buffer distance (red circle). If we only wanted counties that are fully within the buffer, we can use ST_DFullyWithin (see
here for documentation).
What Next?
I plan to continue to learn more and postgres and PostGIS functions and hopefully have more posts about them in the future. One thing to mention is BigQuery, a sql-like database server provided by Google that supports spatial data. The syntax is extremely similar to PostGIS (as far as I can tell). Google gives a decent amount of free credits per month, so it’s worth giving a try. The advantage is that your database will live on Google’s servers and not on your local computer, so it can be accessed from anywhere at anytime. I hope to explore this product and integration to a web platform in the future.
This is the first in hopefully more data science tutorial series. Please feel free to leave feedback or comments.
Session Info
## R version 4.0.3 (2020-10-10)
## Platform: x86_64-w64-mingw32/x64 (64-bit)
## Running under: Windows 10 x64 (build 19042)
##
## Matrix products: default
##
## locale:
## [1] LC_COLLATE=English_United States.1252
## [2] LC_CTYPE=English_United States.1252
## [3] LC_MONETARY=English_United States.1252
## [4] LC_NUMERIC=C
## [5] LC_TIME=English_United States.1252
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] RPostgres_1.3.3 DBI_1.1.0 htmlwidgets_1.5.3 mapview_2.9.0
## [5] leaflet_2.0.4.1 sf_0.9-7 forcats_0.5.0 stringr_1.4.0
## [9] dplyr_1.0.2 purrr_0.3.4 readr_1.4.0 tidyr_1.1.2
## [13] tibble_3.0.4 ggplot2_3.3.2 tidyverse_1.3.0 tigris_1.4
## [17] tidycensus_1.0
##
## loaded via a namespace (and not attached):
## [1] fs_1.5.0 satellite_1.0.2 lubridate_1.7.9.2
## [4] bit64_4.0.5 webshot_0.5.2 httr_1.4.2
## [7] tools_4.0.3 backports_1.2.0 utf8_1.1.4
## [10] rgdal_1.5-21 R6_2.5.0 KernSmooth_2.23-17
## [13] colorspace_2.0-0 raster_3.4-5 withr_2.3.0
## [16] sp_1.4-5 tidyselect_1.1.0 bit_4.0.4
## [19] compiler_4.0.3 leafem_0.1.3 cli_3.0.0
## [22] rvest_0.3.6 xml2_1.3.2 bookdown_0.22
## [25] scales_1.1.1 classInt_0.4-3 rappdirs_0.3.1
## [28] systemfonts_1.0.2 digest_0.6.27 foreign_0.8-80
## [31] svglite_2.0.0 rmarkdown_2.6 base64enc_0.1-3
## [34] pkgconfig_2.0.3 htmltools_0.5.1.1 dbplyr_2.0.0
## [37] rlang_0.4.10 readxl_1.3.1 rstudioapi_0.13
## [40] farver_2.0.3 generics_0.1.0 jsonlite_1.7.2
## [43] crosstalk_1.1.1 magrittr_2.0.1 fansi_0.4.1
## [46] Rcpp_1.0.7 munsell_0.5.0 lifecycle_0.2.0
## [49] stringi_1.5.3 yaml_2.2.1 grid_4.0.3
## [52] maptools_1.1-1 blob_1.2.1 crayon_1.3.4
## [55] lattice_0.20-41 haven_2.3.1 hms_0.5.3
## [58] leafpop_0.1.0 knitr_1.30 pillar_1.4.7
## [61] uuid_0.1-4 codetools_0.2-16 stats4_4.0.3
## [64] reprex_0.3.0 glue_1.4.2 evaluate_0.14
## [67] blogdown_1.3 leaflet.providers_1.9.0 modelr_0.1.8
## [70] png_0.1-7 vctrs_0.3.5 cellranger_1.1.0
## [73] gtable_0.3.0 assertthat_0.2.1 xfun_0.24
## [76] broom_0.7.3 e1071_1.7-4 class_7.3-17
## [79] units_0.6-7 ellipsis_0.3.1 brew_1.0-6
- Posted on:
- July 31, 2021
- Length:
- 27 minute read, 5750 words